Recent Updates
- Feb 8, 2022 Please check out this page for information on paper submission.
- Feb 5, 2022 Rankings are out.
- Jan 25, 2022 Test phase duration is increased by 2 days. New end date Jan 30 23:59 UTC.
- Jan 04, 2022 FAQs about test phase are answered.
- Oct 28, 2021 Submission site on Codalab is open now. Register now!
- Oct 25, 2021 Updated information on participation and preparing submissions.
- Sep 10, 2021 A Baseline system with dev set results is available.
- Join us in Slack.
- Sep 03, 2021 Training data is available.
- Aug 23, 2021 Competition page has some trial data.
Important Dates
| Trial Data Ready |
|
| Training Data Ready |
|
| Evaluation Start |
|
| Evaluation End |
|
| System Description Paper Submission Due |
|
| Notification to Authors |
|
| Camera-ready Due | Apr 21 (Thu), 2022 |
| Workshop | 14-15 July 2022 co-located with NAACL |
FAQs
1. When the test data will be available?
The evaluation phase will start on 24th January 00:00 UTC and end on 28th January 23:59 UTC. Test data will be made available in Codalab prior the start period. As we will follow the UTC timezone, please convert the time to your local time beforehand to avoid any confusion.
2. How can I participate in the test phase?
A new Codalab submission site will be available before the evaluation phase. We will notify every participants from the practice phase with the link to the submission site for the test phase. Test predictions should be submitted to that site. For each track maximum 6 submissions are allowed. The best result will be used.
3. How large will be the test data?
The test data for each language will have at least 150K+ instances and for some languages there are approximately 500K+ instances. As a result, generating predictions can take longer.
4. How the final ranking will be determined? Will it consider per-domain F1?
Per-domain F1 will be shown in output JSON file, but final ranking will be determined based on overall macro-F1.
5. Will I be able to see my results and the leaderboard during the test phase?
You can see the results on your submissions, but the leaderboard will not be available until after the competition.
6. Can we use an ensemble-based approach?
Yes, you can use any model for the task.
7. What are the domains of the test data?
The test data domains are similar as the development data. Looking at the development set will give an idea on the domains.
8. How much of the test entities overlap with the training entities?
This table provides the percentage of test data entities that are also found in the training sets.
| LOC | PER | PROD | GRP | CORP | CW | |
|---|---|---|---|---|---|---|
| BN - Bangla | 3.99 | 1.54 | 34.66 | 7.15 | 23.85 | 4.33 |
| DE - German | 3.28 | 2.76 | 6.54 | 5.68 | 6.18 | 3.7 |
| EN - English | 0.23 | 0.15 | 0.56 | 0.38 | 0.51 | 0.2 |
| ES - Spanish | 0.39 | 0.22 | 0.58 | 0.38 | 0.55 | 0.26 |
| FA - Farsi | 3.28 | 4.39 | 8.62 | 9.83 | 12.06 | 5.9 |
| HI - Hindi | 4.84 | 1.87 | 30.33 | 14.78 | 21.24 | 4.87 |
| KO - Korean | 5.73 | 5.49 | 12.32 | 8.51 | 11.24 | 7.2 |
| NL - Dutch | 3.75 | 3.7 | 6.61 | 5.12 | 6.02 | 4.53 |
| RU - Russian | 3.15 | 1.36 | 5.65 | 3.91 | 5.63 | 3.82 |
| TR - Turkish | 0.61 | 0.34 | 1.72 | 0.83 | 1.64 | 0.59 |
| ZH - Chinese | 4.28 | 1.58 | 15.38 | 1.38 | 7.65 | 5.35 |
9. How is the label distribution in the test data?
The plot below shows the label distribution in the train and test data. Y axis indicates the percentage of a particular label in the data.
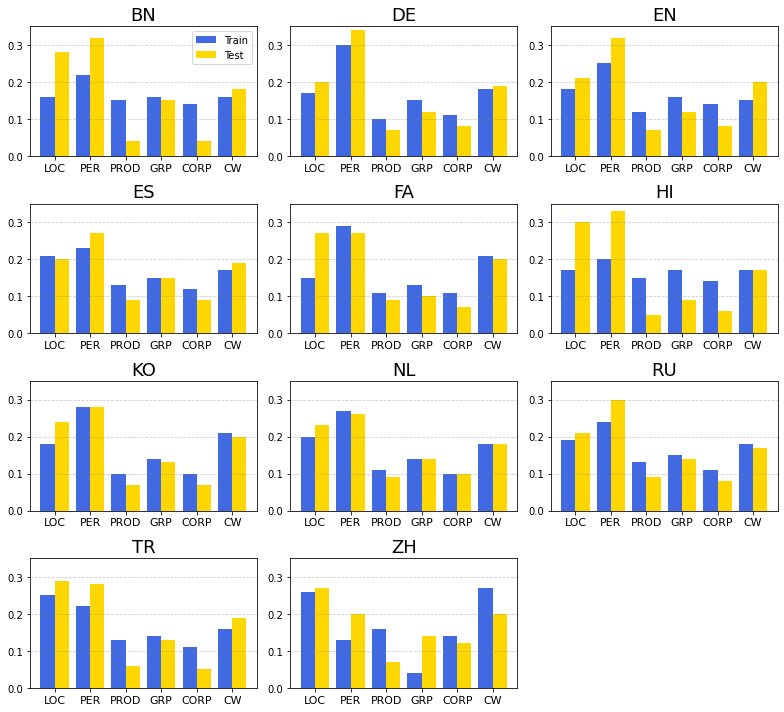
10. How many unique entities are there?
This plot shows the total number of unique entities in the train and test sets.
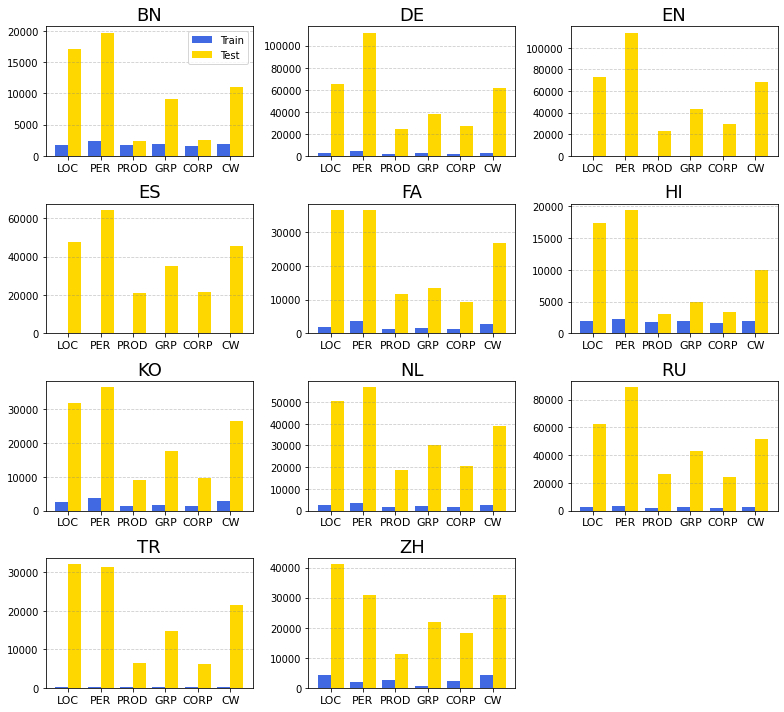
11. Since the test set is large, is there a way to efficiently output token tags for models using subword tokenizers?
We have implemented a method for doing this step. More details available here.