Recent Updates
- Feb 8, 2022 Please check out this page for information on paper submission.
- Feb 5, 2022 Rankings are out.
- Jan 25, 2022 Test phase duration is increased by 2 days. New end date Jan 30 23:59 UTC.
- Jan 04, 2022 FAQs about test phase are answered.
- Oct 28, 2021 Submission site on Codalab is open now. Register now!
- Oct 25, 2021 Updated information on participation and preparing submissions.
- Sep 10, 2021 A Baseline system with dev set results is available.
- Join us in Slack.
- Sep 03, 2021 Training data is available.
- Aug 23, 2021 Competition page has some trial data.
Important Dates
| Trial Data Ready |
|
| Training Data Ready |
|
| Evaluation Start |
|
| Evaluation End |
|
| System Description Paper Submission Due |
|
| Notification to Authors |
|
| Camera-ready Due | Apr 21 (Thu), 2022 |
| Workshop | 14-15 July 2022 co-located with NAACL |
The competition is over. The dataset is publicly available. You can check out the post-evaluation phase here.
1. How to Participate
- The organizers have defined a task (i.e., NER) and released the training data on September 3rd. The task is divided across several languages as subtasks. The participants can work on as many as languages they want to.
- Participants can form a team with multiple people or single person team is okay.
- The participants can access the training data after filling the form in the Dataset page.
- The participants can experiment with the training data to develop models. Usage of any external data or resource is allowed and highly encouraged. This process can run till the evaluation period.
- Evaluation period: On January 24th, the organizers will release the test set containing instances without the labels. The participants will use their developed models to predict the labels for the instances and they have to create a submission file that follows exactly the same format of the training data. These prediction files should be submitted to Codalab submission portal (will be announced later). These predictions will be compared against the ground truth labels of the test data and the teams will be ranked on a leaderboard according to the performance score.
- Each team is encouraged to write a system description paper describing their submission system, analysis of their results, interesting insights and submit before around February 23rd, 2022. Paper submission procedure will be announced later. After a review period, each team has to update their submitted paper based on the review feedback and submit the camera ready version. Accepted papers will be published as part of the proceedings of SemEval 2022 Workshop.
- To connect with the organizers or other participants about any questions or discussions, participants can join the Slack and Google group.
2. Training Data Format
Click here to download a small set of trial data in English.
We will follow the CoNLL format for the datasets. Here is an example data sample from the trial data.
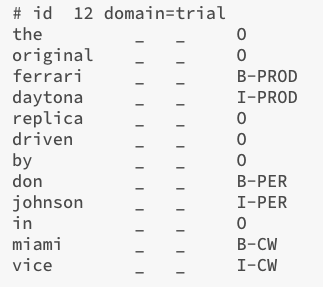
In a data file, samples are separated by blank lines. Each data instance is tokenized and each line contains a single token with the associated label in the last (4th) column. Second and third columns (_) are ignored. Entities are labeled using the BIO scheme. That means, a token tagged as O is not part of an entity, B-X means the token is the first token of an X entity, I-X means the token is in the boundary (but not the first token) of an X type entity having multiple tokens. In the given example, the input text is:
the original ferrari daytona replica driven by don johnson in miami vice
The following image shows the entities as annotated.

Here are some examples from the other languages.
- Bangla:

- Chinese:

- Hindi:

- Korean:

- German:

- Russian:
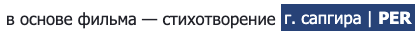
- Turkish:

- Farsi:

- Dutch:

- Spanish:

3. Label Space
In this task, we focus on the following six entity types:
- PER : Person
- LOC : Location
- GRP : Group
- CORP : Corporation
- PROD : Product
- CW: Creative Work
4. Evaluation
In this shared task, we provide train/dev/test data for 11 languages. Additionally, we provide dev and test sets for code-mixed language (Find relevant resources in Section 6). As a summary, we provide 11 training files and 12 dev/test files. This codalab competition is in practice phase, where you are allowed to submit prediction file for dev sets. The evaluation framework is divided in three broad tracks.
-
Multi-lingual (Track 1): In this track, the participants have to train a single multi-lingual NER model using training data for all the languages. This model should be used to generate prediction files for each of the 11 languages’ evaluation (dev/test) set and a code-mixed evaluation set. That means the model should be able to handle monolingual data from any of the languages and code-mixed cases as well.
Predictions from any mono-lingual model is not allowed in this track. Therefore, please do not submit predictions from mono-lingual models in this track.. -
Mono-lingual (Tack 2-12): In this track, the participants have to train a model that works for only one language. For each language, there will be one dev/test set that contains examples for that particular language. Participants have to train a mono-lingual model for the language of their interest and use that to create prediction file for the evaluation set of that language.
Predictions from any multi-lingual model is not allowed in this track. -
Code-mixed (Tack 13): This test data contains have code-mixed samples. These samples will include tokens from any of the 11 mentioned languages in the shared task. This is an additional test set apart from the 11 mono-lingual test sets.
5. Submission Instructions
The evaluation script is based on conlleval.pl.
5.1. Format of prediction file
The prediction file should follow CoNLL format but only contain tags. That means, each line contains only the predicted tags of the tokens and sentences are separated by a blank line. Make sure your tags in your prediction file are exactly aligned with the provide dev/test sets. For example,
- Given
en_dev.conlloren_test.conll-
# id f423a88e-02b7-4d61-a546-4a1bd89cfa15 domain=dev it _ _ _ originally _ _ _ operated _ _ _ seven _ _ _ bus _ _ _ routes _ _ _ which _ _ _ were _ _ _ mainly _ _ _ supermarket _ _ _ routes _ _ _ for _ _ _ asda _ _ _ and _ _ _ tesco _ _ _ . _ _ _ ...
-
- You will need generate the prediction file
en.pred.conllin the follow format-
#(You can either delete sentence id or keep it) O O O O O O O O O O O O B-CORP O B-CORP O ...
-
5.2. Prepare submission files
Follow the below instructions to submit your prediction files for a track. Codalab requires all submissions in zip format
- Use your trained model to generate a prediction file for a specific tack and name it in this format:
<language_code>.pred.conll.- For example, when you participate in the English track, you will need to generate a prediction file for en_dev.conll (or en_test.conll in the testing phase) and name it as en.pred.conll.
- The language_code values for Track 12 Multilingual and Track 13 code mixed are multi and mix, respectively. That means, you will need to name the prediction file as
multi.pred.conllormix.pred.conll.
- Compress the
<language_code>.pred.conllfile to a zip file by using zipmy_submission.zip <language_code>.pred.conll(or your favorite zip utility), and the submit the zip file to the right track on Codalab.
6. Some Resources for the Beginners in NLP
- Wikipedia article on Named Entity Recognition
- Lecture from Prof. Chris Manning on the Evaluation of Named Entity Recognition
- Named Entity Recognition (NER) using spaCy in Python
- Custom Named Entity Recognition (NER) model with spaCy 3 in Four Steps
- Named Entity Recognition using Transformers with Keras
- Named Entity Recognition Tagging with Pytorch
- How to Fine tune BERT for NER
- Recent SOTA Papers for NER systems in NLP Progress
- Code Switching Leaderboard LinCE.
- Named Entity Recognition on Code-Switched Data: Overview of the CALCS 2018 Shared Task
Communication
-
Join us in Slack
-
Subscribe to the task mailing list