Recent Updates
- Feb 8, 2022 Please check out this page for information on paper submission.
- Feb 5, 2022 Rankings are out.
- Jan 25, 2022 Test phase duration is increased by 2 days. New end date Jan 30 23:59 UTC.
- Jan 04, 2022 FAQs about test phase are answered.
- Oct 28, 2021 Submission site on Codalab is open now. Register now!
- Oct 25, 2021 Updated information on participation and preparing submissions.
- Sep 10, 2021 A Baseline system with dev set results is available.
- Join us in Slack.
- Sep 03, 2021 Training data is available.
- Aug 23, 2021 Competition page has some trial data.
Important Dates
| Trial Data Ready |
|
| Training Data Ready |
|
| Evaluation Start |
|
| Evaluation End |
|
| System Description Paper Submission Due |
|
| Notification to Authors |
|
| Camera-ready Due | Apr 21 (Thu), 2022 |
| Workshop | 14-15 July 2022 co-located with NAACL |
Check out the Task Overview Paper.
Check out the Dataset Paper (COLING 2022).
This shared task challenges NLP enthusiasts to develop complex Named Entity Recognition systems for 11 languages. The task focuses on detecting semantically ambiguous and complex entities in short and low-context settings. Participants are welcome to build NER systems for any number of languages. And we encourage to aim for a bigger challenge of building NER systems for multiple languages. The languages are: English, Spanish, Dutch, Russian, Turkish, Korean, Farsi, German, Chinese, Hindi, and Bangla. For some languages, an additional track with code-mixed data will be offered. The task also aims at testing the domain adaption capability of the systems by testing on additional test sets on questions and short search queries.
Highlights of the task
- Task organizers will provide entity annotated training data for 11 languages.
- Participants can use the data to build NER model for one or more languages.
- Task organizers will provide test data without the annotations. The participants have to use their systems to correctly detect the entities and submit the predictions to Codalab page.
- Task organizers will rank the submissions based on their performance on each language, separately.
- Participants are encouraged to aim for a bigger challenge to build NER systems for multiple languages. It can be one model per language or a single model for multiple languages.
Data Examples
Here are some examples from all the 11 languages.
The entities are highlighted with the entity type.
- Bangla:

- Chinese:

- English:

- Hindi:

- Korean:

- German:

- Russian:
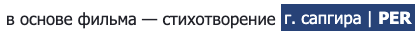
- Turkish:

- Farsi:

- Dutch:

- Spanish:

Motivation
Processing complex and ambiguous Named Entities (NEs) is a challenging NLP task in practical and open-domain settings, but has not received sufficient attention from the research community.
Complex NEs, like the titles of creative works (movie/book/song/software names) are not simple nouns and are harder to recognize (Ashwini and Choi, 2014). They can take the form of any linguistic constituent, like an imperative clause (“Dial M for Murder”), and do not look like traditional NEs (Person names, locations, organizations). This syntactic ambiguity makes it challenging to recognize them based on their context. Such titles can also be semantically ambiguous, e.g., “On the Beach” can be a preposition or refer to a movie. Finally, such entities usually grow at a faster rate than traditional categories, and emerging entities pose yet another challenge. Table 1 lists more details about these challenges, and how they can be evaluated.
Neural models (e.g., Transformers) have produced high scores on benchmark datasets like CoNLL03/OntoNotes (Devlin et al., 2019). However, as noted by Augenstein et al. (2017), these scores are driven by the use of well-formed news text, the presence of “easy” entities (person names), and memorization due to entity overlap between train/test sets; these models perform significantly worse on complex/unseen entities. Researchers using NER on downstream tasks have noted that a significant proportion of their errors are due to NER systems failing to recognize complex entities (Luken et al., 2018; Hanselowski et al., 2018).

References
- Sandeep Ashwini and Jinho D. Choi. 2014. Targetable named entity recognition in social media. CoRR, abs/1408.0782.
- Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: pre-training of deep bidirectional transformers for language understanding. In NAACL-HLT (1). Association for Computational Linguistics.
- Isabelle Augenstein, Leon Derczynski, and Kalina Bontcheva. 2017. Generalisation in named entity recognition: A quantitative analysis. Computer Speech & Language, 44:61–83.
- Jackson Luken, Nanjiang Jiang, and Marie-Catherine de Marneffe. 2018. QED: A fact verification system for the FEVER shared task. In Proceedings of the First Workshop on Fact Extraction and VERification (FEVER), pages 156–160, Brussels, Belgium. Association for Computational Linguistics.
- Andreas Hanselowski, Hao Zhang, Zile Li, Daniil Sorokin, Benjamin Schiller, Claudia Schulz, and Iryna Gurevych. 2018. UKP-athene: Multi-sentence textual entailment for claim verification. In Proceedings of the First Workshop on Fact Extraction and VERification (FEVER), pages 103–108, Brussels, Belgium. Association for Computational Linguistics.
Communication
-
Join us in Slack
-
Subscribe to the task mailing list
Anti-Harassment Policy
SemEval highly values the open exchange of ideas, freedom of thought and expression, and respectful scientific debate. We support and uphold the NAACL Anti-Harassment policy. Participants are encouraged to send any concerns or questions to the NAACL Board members, Priscilla Rasmussen and/or the workshop organizers.