Recent Updates
- Feb 20, 2023 Papers should be submitted here
- Feb 7, 2023 Please check out this page for information on paper submission.
- Feb 7, 2023 Rankings are out.
- Jan 25, 2023 Evaluation phase is extended by 24 hours. This phase will end on February 1st 11:59 pm AOE.
- Jan 25, 2023 Evaluation phase site with test data is available in Codalab.
- Jan 18, 2023 Practice phase site on Codalab is open now.
Important Dates
| Trial Data Ready |
|
| Training Data Ready |
|
| Evaluation Start |
|
| Evaluation End |
|
| System Description Paper Submission Due | Feb 28 (Tue), 2023 |
| Notification to Authors | Mar 31 (Fri), 2023 |
| Camera-ready Due | Apr 21 (Fri), 2023 |
| Workshop | 13-14 July 2023 co-located with ACL |
Complex named entities (NE), like the titles of creative works, are not simple nouns and pose challenges for NER systems (Ashwini and Choi, 2014). They can take the form of any linguistic constituent, like an imperative clause (“Dial M for Murder”), and do not look like traditional NEs (Persons, Locations, etc.). This syntactic ambiguity makes it challenging to recognize them based on context. We organized the MultiCoNER task (Malmasi et al., 2022) at SemEval-2022 to address these challenges in 11 languages, receiving a very positive community response with 34 system papers. Results confirmed the challenges of processing complex and long-tail NEs: even the largest pre-trained Transformers did not achieve top performance without external knowledge. The top systems infused transformers with knowledge bases and gazetteers. However, such solutions are brittle against out of knowledge-base entities and noisy scenarios like the presence of spelling mistakes and typos. We propose MultiCoNER II which represents novel challenges through new tasks that emphasize the shortcomings of the current top models.
MultiCoNER II features complex NER in these languages:
- English
- Spanish
- Hindi
- Bangla
- Chinese
- Swedish
- Farsi
- French
- Italian
- Portugese
- Ukranian
- German
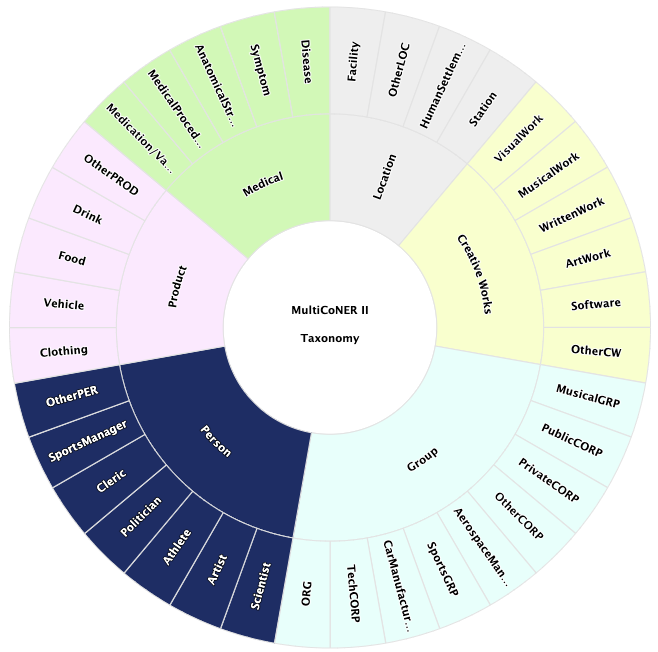
The following figure shows the fine-grained taxonomy of the dataset.
MultiCoNER I: SemEval 2022 Task 11
References
- Sandeep Ashwini and Jinho D. Choi. 2014. Targetable named entity recognition in social media. CoRR, abs/1408.0782.
- Shervin Malmasi, Anjie Fang, Besnik Fetahu, Sudipta Kar, Oleg Rokhlenko. 2022. SemEval-2022 Task 11: Multilingual Complex Named Entity Recognition (MultiCoNER).
Communication
-
Join us in Slack
-
Subscribe to the task mailing list
Anti-Harassment Policy
SemEval highly values the open exchange of ideas, freedom of thought and expression, and respectful scientific debate. We support and uphold the NAACL Anti-Harassment policy. Participants are encouraged to send any concerns or questions to the NAACL Board members, Priscilla Rasmussen and/or the workshop organizers.